

У меня имеется несколько скриптов, полезных для решения разных задач, связанных с форумом и сериалом. При этом область их применения совершенно не ограничивается "Чародеем".
Скрипты (будут) доступны по адресу https://disk.yandex.ru/d/PVbe9LfupL_wVw. Я буду добавлять их туда время от времени, сообщая об обновлениях в этой теме.
Если у вас будут какие-то вопросы по этим скриптам, то не стесняйтесь спрашивать меня в данной теме или личных сообщениях.
Навигатор по теме:
Полезные скрипты
-
Fanat
- Регент

- Сообщения: 1334
- Зарегистрирован: 15 апр 2010, 11:55
- Благодарил (а): 104 раза
- Поблагодарили: 203 раза
get_episode_list.py
Скачать
Иногда бывает полезно иметь под рукой список эпизодов какого-либо сериала. Чтобы не париться с ручным набором названий серий, желательно иметь возможность вытаскивать их откуда-либо автоматически. Очевидным источником такой информации является сайт IMDb - крупнейшая кинематографическая база данных.
IMDb предлагает интерфейс для решения подобных задач, но это стоит денег. Есть и неофициальные бесплатные варианты, в частности на Python, однако они периодически перестают работать из-за смены начинки на сайте IMDb.
В то же время IMDb позволяет скачать огромные архивы с текстовыми файлами, в которых содержится основная информация о всех-всех фильмах, сериалах и их эпизодах, представленных на этом сайте. Идея состоит в том, чтобы автоматически составлять списки эпизодов по данным из этих файлов. Питоновский скрипт get_episode_list.py делает именно это.
Сначала он скачивает и распаковывает указанные архивы - при условии, что их нет в указанной вами папке. Следует отметить, что по состоянию на январь 2024 г. для этих файлов требуется около 1,5 ГБ свободного места (т. к. фильмов в базе IMDb очень-очень много). Если у вас SSD-диск, то лучше его не напрягать такими файлами, а скачать их, например, на флешку.
Затем скрипт анализирует содержимое этих файлов и вытаскивает из него данные по эпизодам указанного вами сериала. Сериал задаётся идентификатором из url-адреса страницы сериала на сайте IMDb. Например, страница сериала "Чародей" имеет адрес https://www.imdb.com/title/tt0112174/; соответственно, идентификатор этого сериала - tt0112174. Вообще, идентификатор сериала (фильма, эпизода) на IMDb всегда начинается с букв tt.
Данные по найденным эпизодам записываются в файлы XLSX и JSON (последний может быть нужен программистам). Вот, например, что получилось для сериала "Пуаро Агаты Кристи":
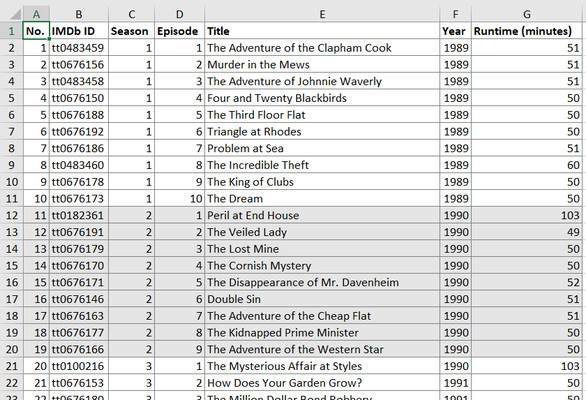
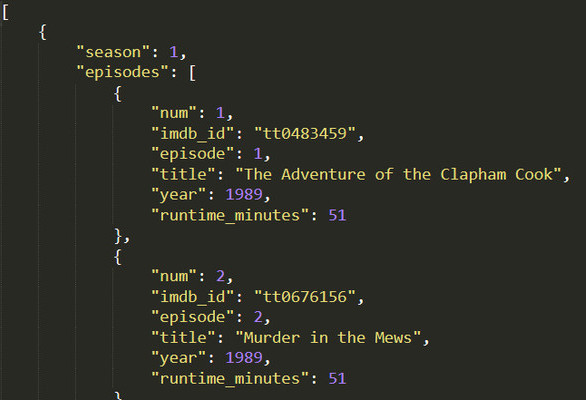
(Обратите внимание, что сезоны в таблице для наглядности раскрашены чередующимися цветами.)
Анализ содержимого файлов осуществляется далеко не самым оптимальным образом. Однако для разового использования этого вполне достаточно. На моём домашнем компьютере для сериала из десятка-другого серий скрипт работает порядка 10 с, а анализ "Санта-Барбары", в которой более 2000 серий, занимает несколько минут.
Надо также отметить, что используемые архивы обновляются на сайте IMDb ежедневно: в них вносятся исправления, добавляются совсем новые фильмы и т. д. Соответственно, для сериалов в стадии показа нужно использовать самые свежие архивы.
Иногда бывает полезно иметь под рукой список эпизодов какого-либо сериала. Чтобы не париться с ручным набором названий серий, желательно иметь возможность вытаскивать их откуда-либо автоматически. Очевидным источником такой информации является сайт IMDb - крупнейшая кинематографическая база данных.
IMDb предлагает интерфейс для решения подобных задач, но это стоит денег. Есть и неофициальные бесплатные варианты, в частности на Python, однако они периодически перестают работать из-за смены начинки на сайте IMDb.
В то же время IMDb позволяет скачать огромные архивы с текстовыми файлами, в которых содержится основная информация о всех-всех фильмах, сериалах и их эпизодах, представленных на этом сайте. Идея состоит в том, чтобы автоматически составлять списки эпизодов по данным из этих файлов. Питоновский скрипт get_episode_list.py делает именно это.
Сначала он скачивает и распаковывает указанные архивы - при условии, что их нет в указанной вами папке. Следует отметить, что по состоянию на январь 2024 г. для этих файлов требуется около 1,5 ГБ свободного места (т. к. фильмов в базе IMDb очень-очень много). Если у вас SSD-диск, то лучше его не напрягать такими файлами, а скачать их, например, на флешку.
Затем скрипт анализирует содержимое этих файлов и вытаскивает из него данные по эпизодам указанного вами сериала. Сериал задаётся идентификатором из url-адреса страницы сериала на сайте IMDb. Например, страница сериала "Чародей" имеет адрес https://www.imdb.com/title/tt0112174/; соответственно, идентификатор этого сериала - tt0112174. Вообще, идентификатор сериала (фильма, эпизода) на IMDb всегда начинается с букв tt.
Данные по найденным эпизодам записываются в файлы XLSX и JSON (последний может быть нужен программистам). Вот, например, что получилось для сериала "Пуаро Агаты Кристи":
(Обратите внимание, что сезоны в таблице для наглядности раскрашены чередующимися цветами.)
Анализ содержимого файлов осуществляется далеко не самым оптимальным образом. Однако для разового использования этого вполне достаточно. На моём домашнем компьютере для сериала из десятка-другого серий скрипт работает порядка 10 с, а анализ "Санта-Барбары", в которой более 2000 серий, занимает несколько минут.
Надо также отметить, что используемые архивы обновляются на сайте IMDb ежедневно: в них вносятся исправления, добавляются совсем новые фильмы и т. д. Соответственно, для сериалов в стадии показа нужно использовать самые свежие архивы.
-
Fanat
- Регент
- Сообщения: 1334
- Зарегистрирован: 15 апр 2010, 11:55
- Благодарил (а): 104 раза
- Поблагодарили: 203 раза
add_img_numbers.py
Скачать
Когда готовишь пост с десятками или сотнями фотографий (например, при написании рассказа о поездке) и вставляешь коды со ссылками на эти изображения одним большим блоком, становится сложно разобраться, какая ссылка на какое фото ведёт. Питоновский скрипт add_img_numbers.py упрощает работу с таким блоком ссылок.
Скрипт берёт код будущего поста с множеством img-ссылок из заданного текстового файла, сканирует его построчно и, если в строке обнаружен тег img в квадратных скобках, вставляет перед такой строкой новую строку с порядковым номером изображения в обрамлении парных дефисов. Код с вставленными номерами сохраняется в новый файл.
Если вставить код с номерами в форум, но не публиковать, а смотреть на него в режиме просмотра нового (будущего) сообщения, то среди моря картинок уже вполне можно ориентироваться, т. к. они отображаются вместе с номерами. Далее необходимо написать сопровождающий текст с комментариями к фотографиям, удаляя при этом их номера шаг за шагом. Публикуемый пост, разумеется, не должен содержать никаких номеров.
Пример кода форумного сообщения до работы скрипта:
После работы скрипта получается следующее:
Когда готовишь пост с десятками или сотнями фотографий (например, при написании рассказа о поездке) и вставляешь коды со ссылками на эти изображения одним большим блоком, становится сложно разобраться, какая ссылка на какое фото ведёт. Питоновский скрипт add_img_numbers.py упрощает работу с таким блоком ссылок.
Скрипт берёт код будущего поста с множеством img-ссылок из заданного текстового файла, сканирует его построчно и, если в строке обнаружен тег img в квадратных скобках, вставляет перед такой строкой новую строку с порядковым номером изображения в обрамлении парных дефисов. Код с вставленными номерами сохраняется в новый файл.
Если вставить код с номерами в форум, но не публиковать, а смотреть на него в режиме просмотра нового (будущего) сообщения, то среди моря картинок уже вполне можно ориентироваться, т. к. они отображаются вместе с номерами. Далее необходимо написать сопровождающий текст с комментариями к фотографиям, удаляя при этом их номера шаг за шагом. Публикуемый пост, разумеется, не должен содержать никаких номеров.
Пример кода форумного сообщения до работы скрипта:
Код: Выделить всё
[img]https://c.spellbinder.tv/fs/users/147/images/m/Jjyf9bvqepHLE_80.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/OEdNjot6ceNuK8Vh.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/HvkKqR2ee3nShL8O.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/R1MZE4VxInLlmJu0.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/FjkdFAr2OhtAUlNv.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/Y3xJzudFKPEW5goC.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/4kvGWp1ccZMDlT38.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/ZQaaermZmpuqIDFK.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/zwZZmdSaYb_fHb3v.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/5HjRHjPmxHKj14Oq.jpg[/img]
[img]https://c.spellbinder.tv/fs/users/147/images/m/Zbt7xlAZyJq_Ux4t.jpg[/img]
Код: Выделить всё
--1--
[img]https://c.spellbinder.tv/fs/users/147/images/m/Jjyf9bvqepHLE_80.jpg[/img]
--2--
[img]https://c.spellbinder.tv/fs/users/147/images/m/OEdNjot6ceNuK8Vh.jpg[/img]
--3--
[img]https://c.spellbinder.tv/fs/users/147/images/m/HvkKqR2ee3nShL8O.jpg[/img]
--4--
[img]https://c.spellbinder.tv/fs/users/147/images/m/R1MZE4VxInLlmJu0.jpg[/img]
--5--
[img]https://c.spellbinder.tv/fs/users/147/images/m/FjkdFAr2OhtAUlNv.jpg[/img]
--6--
[img]https://c.spellbinder.tv/fs/users/147/images/m/Y3xJzudFKPEW5goC.jpg[/img]
--7--
[img]https://c.spellbinder.tv/fs/users/147/images/m/4kvGWp1ccZMDlT38.jpg[/img]
--8--
[img]https://c.spellbinder.tv/fs/users/147/images/m/ZQaaermZmpuqIDFK.jpg[/img]
--9--
[img]https://c.spellbinder.tv/fs/users/147/images/m/zwZZmdSaYb_fHb3v.jpg[/img]
--10--
[img]https://c.spellbinder.tv/fs/users/147/images/m/5HjRHjPmxHKj14Oq.jpg[/img]
--11--
[img]https://c.spellbinder.tv/fs/users/147/images/m/Zbt7xlAZyJq_Ux4t.jpg[/img]
-
Fanat
- Регент
- Сообщения: 1334
- Зарегистрирован: 15 апр 2010, 11:55
- Благодарил (а): 104 раза
- Поблагодарили: 203 раза
color_images_ocr.py
Скачать
Все, наверное, когда-то хотя бы для развлечения занимались распознаванием текста (точнее, оптическим распознаванием символов) на изображениях, но то были чёрные надписи на белом фоне. Если фон разноцветный, как в титрах "Чародея", то необходима предварительная обработка таких изображений, чтобы путем некоторых манипуляций над цветом явно выделить текст и отсечь фон. Это нетрудно сделать в продвинутых графических редакторах, но иногда (например, если изображений много) удобнее автоматизировать процесс.
Питоновский скрипт color_images_ocr.py делает именно это. Ему необходимо указать нижний и верхний пороги для цвета текста. Основное значение этого цвета (в титрах "Чародея" это оттенок жёлтого) можно элементарно узнать почти в любом растровом редакторе, используя инструмент для взятия пробы цвета. Нижний и верхний пороги получаются из него методом проб и ошибок: надо отступить немного вниз и вверх. При этом надо помнить, что скрипт принимает эти два порога в шкале HSV (а не RGB), причём H=0–360, S=0–100, V=0–100.
Если пороги подобраны удачно, то всё получится просто замечательно. Скрипт обойдет по списку файлы с сохраненными кадрами, распознает на них текст и сохранит его в файл.
Для распознавания на компьютере должна быть установлена программа Tesseract, и она должна быть в PATH. Скрипт вызовет её сам.
Возьмем, например, два кадра с титрами:


Скрипт преобразует эти изображения к очень удобному для распознавания виду:


Результат распознавания абсолютно правильный:
Все, наверное, когда-то хотя бы для развлечения занимались распознаванием текста (точнее, оптическим распознаванием символов) на изображениях, но то были чёрные надписи на белом фоне. Если фон разноцветный, как в титрах "Чародея", то необходима предварительная обработка таких изображений, чтобы путем некоторых манипуляций над цветом явно выделить текст и отсечь фон. Это нетрудно сделать в продвинутых графических редакторах, но иногда (например, если изображений много) удобнее автоматизировать процесс.
Питоновский скрипт color_images_ocr.py делает именно это. Ему необходимо указать нижний и верхний пороги для цвета текста. Основное значение этого цвета (в титрах "Чародея" это оттенок жёлтого) можно элементарно узнать почти в любом растровом редакторе, используя инструмент для взятия пробы цвета. Нижний и верхний пороги получаются из него методом проб и ошибок: надо отступить немного вниз и вверх. При этом надо помнить, что скрипт принимает эти два порога в шкале HSV (а не RGB), причём H=0–360, S=0–100, V=0–100.
Если пороги подобраны удачно, то всё получится просто замечательно. Скрипт обойдет по списку файлы с сохраненными кадрами, распознает на них текст и сохранит его в файл.
Для распознавания на компьютере должна быть установлена программа Tesseract, и она должна быть в PATH. Скрипт вызовет её сам.
Возьмем, например, два кадра с титрами:
Скрипт преобразует эти изображения к очень удобному для распознавания виду:
Результат распознавания абсолютно правильный:
Разумеется, с прицелом на титры этот скрипт и писался.Written and created by
MARK SHIRREFS
and
JOHN THOMSON
Paul
ZBYCH TROFIMIUK
Riana
GOSIA PIOTROWSKA
-
Fanat
- Регент
- Сообщения: 1334
- Зарегистрирован: 15 апр 2010, 11:55
- Благодарил (а): 104 раза
- Поблагодарили: 203 раза
ChinaCoords.html
Скачать
Как я уже писал, в Китае используются различные геодезические системы. Для одной и той же пары чисел, обозначающих широту и долготу некоторой точки на территории Китая, разные веб-ресурсы (Google Maps, OSM и т. д.) показывают немного разные локации (с разницей порядка сотен метров). Дополнительная головная боль возникает при использовании планировщика поездок по Китаю на картах Baidu.
Поэтому я написал небольшой код на JavaScript, который работает прямо в интернет-браузере. Вы можете скачать файл ChinaCoords.html, открыть его в браузере и поиграться - всё получится без дополнительных программ.
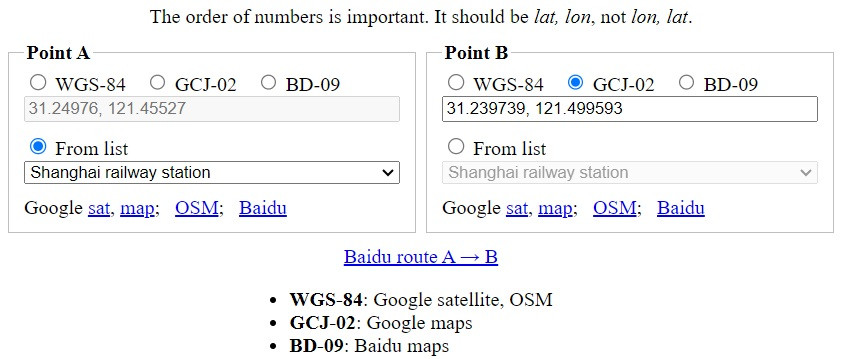
Вам предлагается ввести одну или две точки на территории Китая. Сделать это можно двумя способами:
1) выбрать геодезическую систему (верхний ряд переключателей) и ввести в текстовое поле широту и долготу через запятую;
2) выбрать точку из списка, включающего в себя основные транспортные узлы Шанхая и места съёмок Страны Великого Дракона (разумеется, такой набор объектов выбран с прицелом на гипотетическую поездку по местам съёмок).
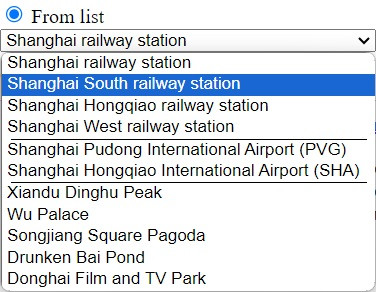
Вариант 1 подразумевает, что вы заранее открыли какой-то сайт с картами (например, Google Maps), нашли там интересующий вас объект и скопировали его координаты. При этом важно правильно указать геодезическую систему в ChinaCoords.html. Чтобы не запутаться, внизу имеется шпаргалка, какая система на каких сайтах используется.
Если вы ввели таким образом две точки (A и B), то можно кликнуть на "Baidu route A → B". В результате откроются карты Baidu с уже проложенным маршрутом между A и B! Единственный минус - маршрут автомобильный. Полагаю, большинству актуальнее общественный транспорт. На него нужно переключиться самостоятельно, кликнув на иконку с автобусом в левом верхнем углу экрана на картах Baidu. Также полезно перевести страницу с китайского на русский или английский с помощью Google Translate, чтобы понимать, о каких пересадках и т. п. идёт речь.
Каждую из введённых точек можно посмотреть на разных картах, для этого есть соответствующие ссылки, идущие подряд в строку. В коде осуществляется пересчёт широты и долготы между разными геодезическими системами; соответствующие функции позаимствованы из Википедии (вряд ли я бы вывел их самостоятельно). Если вас интересует только одна точка на разных картах, а не маршрут, то вторую точку можно и не вводить.
Как я уже писал, в Китае используются различные геодезические системы. Для одной и той же пары чисел, обозначающих широту и долготу некоторой точки на территории Китая, разные веб-ресурсы (Google Maps, OSM и т. д.) показывают немного разные локации (с разницей порядка сотен метров). Дополнительная головная боль возникает при использовании планировщика поездок по Китаю на картах Baidu.
Поэтому я написал небольшой код на JavaScript, который работает прямо в интернет-браузере. Вы можете скачать файл ChinaCoords.html, открыть его в браузере и поиграться - всё получится без дополнительных программ.
Вам предлагается ввести одну или две точки на территории Китая. Сделать это можно двумя способами:
1) выбрать геодезическую систему (верхний ряд переключателей) и ввести в текстовое поле широту и долготу через запятую;
2) выбрать точку из списка, включающего в себя основные транспортные узлы Шанхая и места съёмок Страны Великого Дракона (разумеется, такой набор объектов выбран с прицелом на гипотетическую поездку по местам съёмок).
Вариант 1 подразумевает, что вы заранее открыли какой-то сайт с картами (например, Google Maps), нашли там интересующий вас объект и скопировали его координаты. При этом важно правильно указать геодезическую систему в ChinaCoords.html. Чтобы не запутаться, внизу имеется шпаргалка, какая система на каких сайтах используется.
Если вы ввели таким образом две точки (A и B), то можно кликнуть на "Baidu route A → B". В результате откроются карты Baidu с уже проложенным маршрутом между A и B! Единственный минус - маршрут автомобильный. Полагаю, большинству актуальнее общественный транспорт. На него нужно переключиться самостоятельно, кликнув на иконку с автобусом в левом верхнем углу экрана на картах Baidu. Также полезно перевести страницу с китайского на русский или английский с помощью Google Translate, чтобы понимать, о каких пересадках и т. п. идёт речь.
Каждую из введённых точек можно посмотреть на разных картах, для этого есть соответствующие ссылки, идущие подряд в строку. В коде осуществляется пересчёт широты и долготы между разными геодезическими системами; соответствующие функции позаимствованы из Википедии (вряд ли я бы вывел их самостоятельно). Если вас интересует только одна точка на разных картах, а не маршрут, то вторую точку можно и не вводить.
-
Fanat
- Регент
- Сообщения: 1334
- Зарегистрирован: 15 апр 2010, 11:55
- Благодарил (а): 104 раза
- Поблагодарили: 203 раза
merge_srt.py
Скачать
Я когда-то выкладывал на форуме реплики персонажей отдельными файлами по целым сезонам. Эти файлы были получены склейкой субтитров к отдельным сериям в длинный файл на весь сезон. В склеенный файл рядом с отметками времени добавлялись имена исходных файлов, чтобы было понятно, к какой серии относятся реплики.
Всё это делает скрипт merge_srt.py.
Пусть, например, у нас есть три файла с именами 1x01.eng.srt, 1x02.eng.srt и 1x03.eng.srt, а их содержимое соответственно следующее:
1
00:00:18,100 --> 00:00:21,100
Episode 1
'THE BIG BANG'
2
00:01:13,240 --> 00:01:15,350
What are you doing lurking
there, Katsonis?
1
00:00:10,440 --> 00:00:12,580
Alex!
2
00:00:20,340 --> 00:00:22,080
Hello!
1
00:00:09,840 --> 00:00:11,800
Why did you decide to help me?
2
00:00:12,000 --> 00:00:14,060
You saved my life
and returned my clothes.
Скрипт сделает новый файл, который будет включать в себя содержимое всех исходных файлов подряд:
00:00:18,100 --> 00:00:21,100 // 1x01.eng
Episode 1
'THE BIG BANG'
00:01:13,240 --> 00:01:15,350 // 1x01.eng
What are you doing lurking
there, Katsonis?
00:00:10,440 --> 00:00:12,580 // 1x02.eng
Alex!
00:00:20,340 --> 00:00:22,080 // 1x02.eng
Hello!
00:00:09,840 --> 00:00:11,800 // 1x03.eng
Why did you decide to help me?
00:00:12,000 --> 00:00:14,060 // 1x03.eng
You saved my life
and returned my clothes.
Обратите внимание, что новый файл не содержит номеров блоков субтитров (1, 2 и т. д.), которые имелись в исходных srt-файлах. Эти номера представляются мне совершенно лишними. Также обратите внимание, что рядом с отметками времени появились имена исходных файлов (но без расширения).
Такая игрушка может быть полезна для склейки субтитров к сериям сериалов, чтобы было проще искать реплики персонажей, например.
Я когда-то выкладывал на форуме реплики персонажей отдельными файлами по целым сезонам. Эти файлы были получены склейкой субтитров к отдельным сериям в длинный файл на весь сезон. В склеенный файл рядом с отметками времени добавлялись имена исходных файлов, чтобы было понятно, к какой серии относятся реплики.
Всё это делает скрипт merge_srt.py.
Пусть, например, у нас есть три файла с именами 1x01.eng.srt, 1x02.eng.srt и 1x03.eng.srt, а их содержимое соответственно следующее:
1
00:00:18,100 --> 00:00:21,100
Episode 1
'THE BIG BANG'
2
00:01:13,240 --> 00:01:15,350
What are you doing lurking
there, Katsonis?
1
00:00:10,440 --> 00:00:12,580
Alex!
2
00:00:20,340 --> 00:00:22,080
Hello!
1
00:00:09,840 --> 00:00:11,800
Why did you decide to help me?
2
00:00:12,000 --> 00:00:14,060
You saved my life
and returned my clothes.
Скрипт сделает новый файл, который будет включать в себя содержимое всех исходных файлов подряд:
00:00:18,100 --> 00:00:21,100 // 1x01.eng
Episode 1
'THE BIG BANG'
00:01:13,240 --> 00:01:15,350 // 1x01.eng
What are you doing lurking
there, Katsonis?
00:00:10,440 --> 00:00:12,580 // 1x02.eng
Alex!
00:00:20,340 --> 00:00:22,080 // 1x02.eng
Hello!
00:00:09,840 --> 00:00:11,800 // 1x03.eng
Why did you decide to help me?
00:00:12,000 --> 00:00:14,060 // 1x03.eng
You saved my life
and returned my clothes.
Обратите внимание, что новый файл не содержит номеров блоков субтитров (1, 2 и т. д.), которые имелись в исходных srt-файлах. Эти номера представляются мне совершенно лишними. Также обратите внимание, что рядом с отметками времени появились имена исходных файлов (но без расширения).
Такая игрушка может быть полезна для склейки субтитров к сериям сериалов, чтобы было проще искать реплики персонажей, например.